
深入理解 Claude Code 源码中的 Agent Harness 构建之道
LINK:https://zhuanlan.zhihu.com/p/2025171981390071604
上周,Anthropic 旗下闭源的 AI 编程工具 Claude Code 曝出源码泄露事件。这次事件并非黑客入侵或内部泄密,而是因 npm 打包未排除包含完整源码的 .map 映射文件,导致 1900 余个 Typescript 文件、超 51 万行核心代码意外曝光。相关代码迅速被归档至 Github,数小时内收获超 1100 颗星。
这是迄今为止生产级 AI Agent 系统最完整的一次公开审视,也让外界得以验证此前对 Claude Code 架构的推断,同时窥见其诸多未发布的核心功能与底层设计逻辑。
本文将借助这次源代码泄露机会,顺着一个请求的完整生命周期:从你输入消息到 Agent 交付可工作的代码,我们一步步拆解每个环节。你会发现,LLM 调用本身只是一行代码,真正让 Agent 可用的,是围绕这行代码精心设计的 Agent Harness。
Agent Harness 的核心循环
在深入细节之前,让我们先看看整个系统的全貌。整个 Agent 由 query.ts 中的一个名为 query() 的异步生成器函数驱动,代码库中的其他所有内容都为这个函数服务。
当你输入一条消息并按下回车时,会发生什么?
你输入一条消息
↓
步骤 1:组装上下文
(系统提示词 + CLAUDE.md 文件 + 记忆 + 对话历史)
↓
步骤 2:调用 Claude API
(流式传输,通过异步生成器)
↓
步骤 3:解析响应
(文本块 + tool_use 块)
↓
步骤 4:检查权限
(拒绝规则 → 允许规则 → 分类器 → 询问用户)
↓
步骤 5:执行工具
(只读操作并行执行,写操作串行执行)
↓
步骤 6:反馈结果
(工具结果变成对话中的消息)
↓
步骤 7:上下文检查
(太大?压缩。否则,回到步骤 2)
↓
步骤 8:终止
(没有更多工具调用?完成。出错?恢复或退出)循环的示意图:
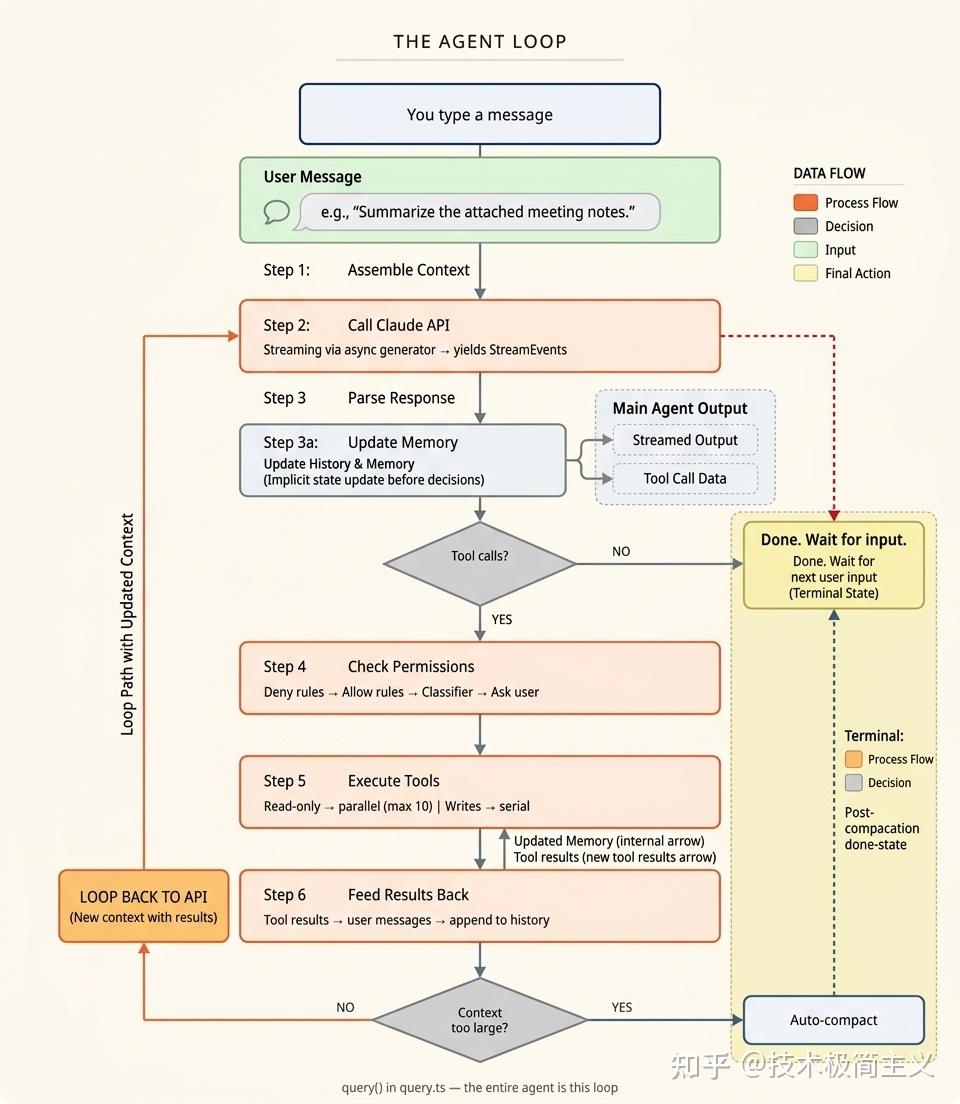
这就是整个 Agent 的完整循环。六个步骤,不断循环,直到任务完成。让我们逐一走过每一步。
接下来,我们逐个拆解。
步骤 1:上下文组装
一切其实从准备上下文开始。在 Claude Code 第一次发起 API 调用之前,它需要把模型用到的所有信息先整理好,而且这一步比想象中要复杂。
系统提示词是通过一个叫 buildEffectiveSystemPrompt() 的函数拼出来的。它不是简单的一段字符串,而是拆成了多个部分,比如「环境信息」「工具使用说明」「语气和风格」等等,每一块都有自己对应的生成逻辑。
比如环境这一块,是通过 computeSimpleEnvInfo() 来生成的。它会去读当前工作目录、判断操作系统、看看是不是在 git 仓库里,然后把这些信息整理成一段文本。
为什么要拆成这样?主要是为了做缓存。这里其实分两类:
缓存部分:只算一次,后面每一轮直接复用。只有在你执行 /clear 或 /compact 的时候才会重新生成。大多数信息都属于这一类,比如操作系统、项目结构,这些东西在会话过程中基本不会变。
非缓存部分:每一轮都会重新计算。因为这些内容可能随时变化,如果不重新生成,就没法复用提示词缓存。目前基本只有一类属于这种情况:MCP 服务器相关的指令,因为它在会话过程中可能随时连接或断开。
这些部分本身被组织成两组,用 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 标记分隔。边界之前的所有内容可以使用 API 的全局缓存范围(在所有用户之间共享)。边界之后的内容是会话特定的。这是一种巧妙的方式,可以避免在每一轮都重新计算整个提示词。
这是组装后的系统提示词实际包含的内容:
| 部分 | 是否缓存 | 内容说明 |
|---|---|---|
| 介绍 | 是 | 角色定义、安全指令、URL 处理规则 |
| 系统 | 是 | 工具调用规则、权限行为、上下文压缩策略 |
| 执行任务 | 是 | 编码规范、验证方式、安全要求 |
| 操作 | 是 | 风险控制:可逆性检查、破坏性操作提示 |
| 使用工具 | 是 | 工具使用偏好(比如用 Read 而不是 cat) |
| 语调和风格 | 是 | 输出风格、简洁性、代码引用格式 |
| 会话指导 | 是 | 当前可用能力、Agent 类型说明 |
| 记忆(CLAUDE.md) | 是 | 项目里的约定和规则 |
| 环境 | 是 | 工作目录、git 状态、系统信息等 |
| MCP 指令 | 否 | 当前连接的 MCP 服务(会动态变化) |
| 总结结果 | 是 | 用于在上下文被清理前保留关键信息 |
比如环境这一块,最后拼出来大概就是这样一段信息:
# Environment
You have been invoked in the following environment:
- Primary working directory: /Users/me/projects/myapp
- Is a git repository: true
- Platform: darwin
- Shell: zsh
- OS Version: Darwin 25.3.0
- You are powered by the model named Claude Opus 4.6.
- Assistant knowledge cutoff is May 2025.「工具使用」这一块也类似,本质上就是一组很明确的规则:
Do NOT use the Bash tool to run commands when a relevant
dedicated tool is provided:
- To read files use Read instead of cat, head, tail, or sed
- To edit files use Edit instead of sed or awk
- To create files use Write instead of cat with heredoc
- To search for files use Glob instead of find or ls
- To search file contents use Grep instead of grep or rg这就是为什么 Claude Code 偏好自己的 FileReadTool 而不是在 bash 中运行 cat。这不是模型的偏好,而是系统提示词中的明确指令。
提示词组装还有一个优先级系统。如果你正常运行 Claude Code,你会得到默认系统提示词。但如果你使用 --system-prompt 标志,它会替换默认值。如果你在自定义 Agent(定义在 .claude/agents/ 中)中运行,Agent 的提示词可以替换或追加到默认值。如果协调器模式处于活动状态,整个提示词会被交换为协调器特定的版本。
组装好系统提示词后,CLAUDE.md 文件会叠加在上面。这是 Claude Code 获取项目特定指令的地方。
CLAUDE.md 文件是怎么被找到的
getMemoryFiles() 函数从当前工作目录向上遍历到文件系统根目录,在每个级别收集指令文件。加载顺序很重要:
- 系统级(托管):
/etc/claude-code/CLAUDE.md和/etc/claude-code/.claude/rules/*.md。这些是在企业环境中使用 Claude Code 时的指令。 - 用户级:
~/.claude/CLAUDE.md和~/.claude/rules/*.md。你应用于每个项目的个人指令。 - 项目级:对于从文件系统根目录到当前工作目录的每个目录,它会加载:
CLAUDE.md.claude/CLAUDE.md.claude/rules/*.md
4. 本地级:每个层级的 CLAUDE.local.md。这些被 gitignore,用于你不想要提交的指令。
遍历从根目录向下进行,因此最近的文件具有最高优先级。如果你在 /Users/me/projects/myapp/src/ 工作,真实的加载过程如下:
加载的文件(按顺序):
1. /etc/claude-code/CLAUDE.md (系统)
2. ~/.claude/CLAUDE.md (用户)
3. ~/.claude/rules/always-use-typescript.md (用户)
4. /Users/me/projects/CLAUDE.md (项目)
5. /Users/me/projects/myapp/CLAUDE.md (项目)
6. /Users/me/projects/myapp/.claude/CLAUDE.md (项目)
7. /Users/me/projects/myapp/.claude/rules/api.md (项目)
8. /Users/me/projects/myapp/CLAUDE.local.md (本地)每个文件被加载后,解析其内容,剥离 HTML 注释,解析 @include 指令(最多 5 层深度)。@include 语法让一个 CLAUDE.md 文件可以拉入另一个文件的内容:
# CLAUDE.md
See our API conventions:
@./docs/api-conventions.md
And our testing standards:
@./docs/testing.md整个函数是带缓存的(只在会话里跑一次),而且对 git worktree 也做了处理,避免重复加载同一份规则,同时也会遵守你配置的排除路径。
完整的上下文包
当系统提示词和 CLAUDE.md 文件组装完成后,getAttachmentMessages() 会拉取其他所有内容:
- 记忆文件:来自
~/.claude/projects//memory/MEMORY.md的持久记忆 - 任务/待办列表:会话期间创建的活动任务
- MCP 服务器指令:已连接的 MCP 服务器文档
- 技能发现结果:匹配当前上下文的可用技能
- 对话历史:当前会话的所有消息
所有这些都被打包到 API 调用中。所以当你输入「修复登录 bug」时,实际发送给 Claude 的内容,大致是这样:
系统提示词: ~15,000 tokens(角色、规则、工具、环境)
CLAUDE.md 文件: ~2,000 tokens(项目指令)
记忆: ~500 tokens(过往会话的相关记忆)
MCP 指令: ~300 tokens(已连接的服务器文档)
对话历史: ~5,000 tokens(当前会话的前几轮)
你的消息: ~10 tokens("修复登录 bug")总而言之,上下文不只是「你的消息」。它是你的消息,加上你的项目规则,加上你的个人偏好,加上 Agent 的记忆,加上对话历史。这就是上下文工程的实践,也是 Agent 成败的关键因素。
技能是怎么被用起来的
在组装上下文的时候,还会顺带做一件事:把可用的技能列出来。
这些技能其实就是一组可复用的提示词,可能来自项目里的 .claude/skills/,也可能是你用户目录下的,甚至还能从 MCP 服务里获取。getSkillListingAttachments() 会把它们收集起来,只保留名字和简单描述,然后塞进系统提示词里。
模型会看到类似这样的内容:
The following skills are available for use with the Skill tool:
- commit: Create a new git commit with a descriptive message.
- review-pr: Review a pull request for code quality and correctness.
- write-blog: Write blog posts for siddharthbharath.com.
当用户的请求匹配一个技能时,模型会使用技能名称调用 SkillTool。
SkillTool 自己的提示词包含一个严格的指令:一旦匹配到技能,就必须先调用工具,不能自己先生成结果。所以模型不会再尝试自己处理这类请求,而是直接把任务交出去。
接下来,技能会在一个独立的子 Agent 里执行,而且有自己的一套上下文。技能对应的提示词(里面可能包含详细指令、示例,甚至参考文件)会被加载到这个「分叉出来」的 Agent 中,由它自己跑完整个流程,最后再把结果返回到主对话。
为了避免技能列表把上下文撑满,系统里做了一层预算控制。
简单来说:
- 所有技能描述加起来,最多占上下文的 1%(200K 模型大概就是 2000 tokens)
- 每个技能的描述不能超过 250 个字符
- 技能太多的话,就按预算自动截断
如果真的需要更详细的信息,模型可以再去调用 ToolSearchTool,按需拿完整定义,而不是一开始就全塞进 prompt。
步骤 2:API调用与异步生成器
上下文准备好之后,就进入调用 API 的阶段了。这一层用的是异步生成器来驱动整个流程。
简单理解,它不是一次性把结果全部算完再返回,而是边生成、边往外输出结果:有一段就给一段,中间可以随时暂停,再继续。
queryLoop() 的无限循环
核心其实就是一个 queryLoop(),里面跑着一个 while (true)。每一轮循环,对应一次完整的 API 往返——Claude Code 本质上就是靠这个循环一直在工作。
每一轮开始时,大致会做这几件事:
- 发一个
stream_request_start事件,通知 UI:要开始请求了 - 控制工具返回的体积(太大的输出会被裁掉,省上下文)
- 必要的话,对之前的回复做一次轻量压缩
- 用
appendSystemContext()拼出最终的系统提示词 - 发起请求,并开始流式接收结果
关键在最后这一步:
模型一边生成 token,一边就通过 StreamEvent 往外输出。终端 UI 收到一段就渲染一段,所以你看到的「逐字输出」,其实就是响应被一块一块实时推出来的结果。
State 对象的状态传递
这个循环之所以能一直跑下去,是因为它会「记住」之前发生的事情。
比如:对话历史、当前有哪些工具可用、错误重试了多少次、有没有做过压缩、现在是第几轮……这些信息都需要在不同轮次之间传下去。
这些状态都放在一个可变的 State 对象里,每一轮循环都会读它、改它,然后再传给下一轮。
比如:
- 压缩上下文后,会更新
state.messages - 因为 token 限制触发重试,会增加
state.maxOutputTokensRecoveryCount - 工具执行改变了能力范围,会更新
state.toolUseContext
关键点在于:每一轮的决策,都会影响下一轮的行为,而这些影响,全都通过这个 State 对象串起来。
步骤 3:响应解析
API 调用完成(或者流结束)。现在我们需要弄清楚 Claude 想要做什么。
解析 Tool Use 块
Claude 的响应其实不是一整段文本,而是一块一块的内容:
text:它要对你说的话tool_use:它想调用的工具
而且这些是在流式过程中一边生成一边解析的,不是等全部返回再处理。
一个典型的 tool_use 长这样:
{
type: 'tool_use',
id: 'toolu_abc123', // 此调用的唯一 ID
name: 'FileEditTool', // 要调用哪个工具
input: { // 工具的参数
file_path: '/Users/me/project/src/app.ts',
old_string: 'const x = 1',
new_string: 'const x = 2'
}
}具体来说,当你让 Claude Code「修复登录 bug」时,它的返回可能是这样的:
[
{ "type": "text", "text": "让我看一下登录代码..." },
{ "type": "tool_use", "id": "toolu_1", "name": "GrepTool",
"input": { "pattern": "login", "glob": "**/*.ts" } },
{ "type": "tool_use", "id": "toolu_2", "name": "GrepTool",
"input": { "pattern": "authenticate", "glob": "**/*.ts" } }
]在同一轮响应里,它可以一边说话,一边发起工具调用。
这里其实就两种情况:
- 没有
tool_use→ 只是对话,直接输出给 UI,这一轮结束 - 有
tool_use→ 说明还没做完,标记needsFollowUp = true,进入下一步去执行这些工具
43 个内置工具
Claude 到底能用哪些工具?其实都在 getAllBaseTools() 里注册好了。下面这些是默认就能用的基础工具:
| 类别 | 工具 |
|---|---|
| 文件 I/O | FileReadTool, FileEditTool, FileWriteTool, NotebookEditTool |
| 搜索 | GlobTool, GrepTool |
| 执行 | BashTool |
| Web | WebFetchTool, WebSearchTool |
| Agents | AgentTool, SendMessageTool |
| 任务 | TaskCreateTool, TaskGetTool, TaskUpdateTool, TaskListTool |
| 规划 | EnterPlanModeTool, ExitPlanModeTool |
| 用户交互 | AskUserQuestionTool |
| 技能 | SkillTool |
| MCP | ListMcpResourcesTool, ReadMcpResourceTool |
还有一类是「条件工具」,只有在特定情况下才会出现。比如在 Node 环境下会有 REPLTool,Windows 下有 PowerShellTool,做调度时会用到 CronCreateTool 和 RemoteTriggerTool,主动模式下还有 SleepTool 之类的。
更关键的是,你接入的 MCP 服务器也会把自己的工具加进来。这些工具都会带上服务器名前缀(比如 mcp_github_create_issue),用来避免和内置工具冲突。同一个服务器只会连接一次,不会重复初始化。
另外,工具是可以控制的。你可以在 settings.json 里直接屏蔽不想用的工具;如果想要更干净的环境,也可以开「简单模式」(CLAUDE_CODE_SIMPLE=1),只保留最基础的 BashTool、FileReadTool 和 FileEditTool。
步骤 4:权限检查
当 Claude 要编辑文件、执行 bash 或写入磁盘时,并不是直接动手,而是先走一遍权限检查。
这里其实是个取舍:权限提示太多,体验会很差,你就会停止使用这个工具。权限提示太少,你的 Agent 又可能会像 OpenClaw 一样 rm -rf 你的项目。
Claude Code 的做法是用一套分层的权限机制。每次调用工具时,都会按顺序经过几层判断,只要其中一层做出决定,就直接结束,不会继续往下走:
工具调用进来
↓
1. 命中拒绝规则 → 直接拦掉
↓
2. 命中允许规则 → 直接放行
↓
3. Bash 分类器 → 异步判断(最多等 2 秒)
↓
4. 交互提示 → 再问你一次这些「允许 / 拒绝」规则都来自你的 Claude Code 配置,比如:
{
"permissions": {
"allow": ["Read", "Glob", "Grep", "BashTool(grep:*)"],
"deny": ["BashTool(rm -rf:*)"]
}
}整个流程是按顺序走的,而且优先看规则,因为它们是最快的。比如你设置了「始终允许 Grep」,那所有 grep 操作都会直接通过,中间不会再打断你。
分类器层位于规则和交互提示之间,主要是帮你自动判断一些 bash 命令该不该放行。
简单来说,它会先「猜一把」:
- 如果判断这是只读操作(比如
git status、ls),就直接放行 - 如果看起来有风险(比如
rm、git push --force),就交给你来确认
另外,这个分类过程是有时间限制的——最多等 2 秒。如果还没判断出来,就直接进入交互提示,不会卡住你。
这是在实际使用中,不同工具调用大概会怎么走这几层流程:
| 工具调用 | 层 1(拒绝) | 层 2(允许) | 层 3(分类器) | 层 4(询问) | 结果 |
|---|---|---|---|---|---|
| GrepTool(“login”) | 通过 | 命中允许规则 | – | – | 自动通过 |
| BashTool(“git status”) | 通过 | 通过 | 判断为只读 | – | 自动通过 |
| BashTool(“rm -rf /”) | 命中拒绝规则 | – | – | – | 直接拦截 |
| FileEditTool(“app.ts”) | 通过 | 通过 | 通过 | 需要确认 | 弹出提示 |
| BashTool(“npm install”) | 通过 | 通过 | 判断不确定(超时) | 需要确认 | 弹出提示 |
这套分层设计的实际体验其实很直观:日常做的事情,比如读文件、搜代码、跑测试,基本都是「无感通过」的,不会被频繁打断;但一旦涉及改文件、执行可能有影响的命令,才会停下来让你确认。
简单说,就是该快的地方尽量快,该谨慎的地方一定谨慎。
步骤 5:工具执行
权限通过之后,就到了真正执行工具的阶段了。这一层其实是整个系统里影响体验的一块。
Claude 在一次响应里,经常会同时给出多个工具调用(有时候一口气 6 个或者 8 个)。如果按最简单的方式,一个个串行执行,整体速度会很慢。Claude Code 在这里做了一个更聪明的设计。
系统里的每个工具都实现了一套统一的接口:
type Tool = {
name: string
description(input, context): string
inputSchema: ZodSchema
execute(input, context): Promise<ToolUseResult>
isConcurrencySafe(input): boolean
isReadOnly(input): boolean
}isConcurrencySafe() 这个方法看起来很小,但作用很关键。它其实就是在标记:这个工具能不能和其他工具一起并发执行。
在执行一批工具调用之前,Claude Code 会先看这个标记,然后把工具分成几组来跑:
- 连续的只读操作会被打包在一起,并发执行(默认最多 10 个)
- 一旦出现写操作,就会单独拿出来,按顺序执行,避免冲突
换句话说:当 Claude 一次要读多个文件时,这些读取是同时进行的;但一旦涉及改文件,就会变成串行执行,确保不会出问题。
举个实际例子。假设你让 Claude 「修复登录 bug」,它可能会给出这样一组工具调用:
来自 Claude 响应的工具调用:
1. GrepTool("login handler") → 只读
2. GrepTool("auth middleware") → 只读
3. GlobTool("**/auth/**/*.ts") → 只读
4. FileEditTool("src/auth/login.ts") → 写
5. FileReadTool("src/auth/test.ts") → 只读
6. FileReadTool("src/auth/types.ts") → 只读partitionToolCalls() 会把这些工具调用拆成几个批次,大致是这样:
批次 1(并发):GrepTool, GrepTool, GlobTool
→ 三个同时跑
批次 2(串行):FileEditTool
→ 单独执行,等前一批结束
批次 3(并发):FileReadTool, FileReadTool
→ 两个一起跑,等写操作完成所以实际执行下来,不是 6 个一步一步跑,而是分成 3 轮。能并发的读取就一起跑,需要独占的写操作就单独执行。
runTools() 的执行方式也很直接:
- 遇到并发批次,就把这一组工具一起触发,各自跑完各自返回结果
- 遇到串行批次,就一个一个执行,前一个结束再跑下一个
这里有个挺关键的小细节:工具是可以修改后续上下文的。
有些工具在返回结果时,会带一个「上下文修改函数」,用来更新 ToolUseContext,从而影响后续的执行,比如切换工作目录、更新缓存,或者调整可用的工具。
处理方式也分两种:
- 并发批次:先把这些修改收集起来,等整批执行完再统一应用(避免并发冲突)
- 串行批次:每个工具执行完就立刻应用
这也是为什么 Claude Code 在「读代码」阶段会感觉特别快:不是一个文件一个文件等着读,而是能一起读的全部并发处理,时间基本被压到最短。
步骤 6:结果反馈
工具执行完之后,下一步会发生什么?
每个工具的执行结果,都会被放进对话里,这样 Claude 才能知道刚刚发生了什么,并决定下一步怎么做。
每个工具结果都会变成一条新的 user 消息,里面带一个 tool_result 内容块。这个块里有一个 toolUseID,用来对应之前那次工具调用。
可以理解成一个来回:
- Claude:我要用工具 X(ID = abc123)
- 系统:这是 abc123 的执行结果
举个例子,如果 Claude 调用了一个 ID 为 toolu_1 的 GrepTool,返回结果会是这样:
{
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": "toolu_1",
"content": "src/auth/login.ts:42: async function handleLogin(req, res) {\\nsrc/auth/login.ts:58: if (!user) return res.status(401)\\n..."
}]
}Claude 拿到 grep 的结果后,就可以决定下一步了:是去读具体文件、直接修改,还是继续补充更多上下文。
回到主循环(query.ts),这些工具返回的结果会被统一收集起来,然后追加到对话历史里,作为下一轮决策的输入。
const next: State = {
messages: [...messagesForQuery, ...assistantMessages, ...toolResults],
// ...
}接下来,流程会回到步骤 2。Claude 会带着更新后的上下文(包括刚才的工具结果)再次被调用,然后决定下一步要做什么:
- 有时候它会继续查信息、再调几个工具
- 有时候信息已经够了,就开始写代码
- 也可能是在测试结果里发现问题,转头去修 bug。
这其实就是 Agent 循环的实际运作方式:一轮一轮往前推进。每跑一轮,都会多一些上下文。模型会基于「刚刚发生了什么」来调整下一步,而不是从零开始。
另外,在每一轮之间,系统还会悄悄做一些「补充上下文」的工作:
- 重新跑一遍
getAttachmentMessages(),看看有没有新的记忆文件或任务更新 - 如果后台的记忆预取完成了,会把结果加进来
- 如果技能发现找到了更相关的工具或技能,也会补进上下文
换句话说,上下文不是一成不变的,而是在每一轮之间不断增长。
步骤 7:上下文管理
如果你用 Claude Code 一段时间,应该会遇到一个情况:对话变长之后,它会提示你「需要压缩上下文」。这是因为上下文不是无限的。在最开始组装完上下文之后,系统还会在每一轮循环里持续做管理。
每跑完一轮,它都会检查一件事:现在的上下文有多大了?
因为对话是一直在增长的:
- 历史消息越来越多
- 工具返回的结果(尤其是读文件、跑 bash)可能很大
几轮下来,很容易就接近模型的上下文上限。
所以系统会在每一轮开始时做一次「自动检查」。当距离上限还剩大约 13,000 tokens(默认值)时,就会触发压缩流程。
当触发压缩时,Claude Code 不是只用一种方式,而是分层处理的。
先是微压缩,它发生在每一轮之间。主要处理的是那些「解释性内容」——比如工具调用之间的一大段说明。
简单来说就是:
- 工具的输入 / 输出都会保留
- 中间那些冗长的解释,会被压缩成更短的总结
比如 Claude 在改 5 个文件前写了一大段思路,这一段就会被精简,但具体改了什么、工具返回了什么,都不会丢。
再往上,是更重的一层:会话记忆压缩。这一层会直接对「更早的对话历史」下手,把整段对话总结成一条精简的信息,然后替换掉原始内容。
会话记忆压缩是主要策略。它获取最早的对话历史块,调用 API 以生成简洁的摘要,并用单个 CompactBoundaryMessage 替换原始消息。
效果大概是这样:
[CompactBoundaryMessage]
"用户要求修复登录 bug。我查看了 src/auth/ 相关代码,
包括 login.ts、middleware.ts 和 types.ts。
问题出在 login.ts 第 58 行缺少空检查,用户查询可能返回 undefined。
用户已确认这个判断是正确的。"一条摘要消息,可以直接替代掉几十条历史消息,对话就靠这条「压缩记忆」继续往下走。
除了对话本身,工具调用也会被总结。当 Claude 连续跑很多工具(比如一堆 grep 再加一批文件读取),系统会在后台生成一个精简版本,比如:「在整个代码库中搜索 X,在 A、B、C 文件中找到相关实现,并进一步读取这些文件」。当上下文开始紧张时,这种摘要可以直接替换掉原本冗长的工具输出。
如果前面的策略都没兜住,还有最后一层:反应式压缩。这个不是提前触发的,而是「出事了才会顶上」:当 API 因为 prompt_too_long 直接拒绝请求,系统会立刻捕获这个错误,当场做一次压缩,然后重建请求,再试一遍。
这里还有一个挺有意思的工程细节:系统里专门加了一个「断路器」。
// Stop trying autocompact after this many consecutive failures.
// BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures
// (up to 3,272) in a single session, wasting ~250K API calls/day globally.
const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3注释里说明了历史背景:曾经有 1,279 个会话,在压缩失败后还在不断重试,有的甚至在一个会话里连续失败 3,000+ 次,每天白白浪费大约 25 万次 API 调用。
最后的解决办法是连续失败 3 次后,就不再尝试自动压缩,防止无限循环或大量浪费 API 调用。
步骤 8:终止与错误恢复
循环总会有结束的一刻。最理想的情况其实很简单:Claude 最后一轮只返回了一段文本,没有再调用任何工具。这时 needsFollowUp = false,流程自然收尾,函数返回 { reason: 'completed' }。
但现实不会总这么顺利。一个完整的 Agent 循环,可能在很多不同的节点停下来,而 Claude Code 基本把这些情况都提前考虑到了。
| 终止原因 | 发生了什么 |
|---|---|
| completed | 正常结束,Claude 给出最终答案 |
| max_turns | 跑到最大轮次,被强制收住 |
| aborted_streaming | 用户在生成过程中 Ctrl+C |
| aborted_tools | 工具执行时被用户打断 |
| prompt_too_long | 上下文太大,所有压缩策略都失败 |
| model_error | 模型直接报错,没法恢复 |
| blocking_limit | 禁用自动压缩时达到硬上下文限制 |
| hook_stopped | 外部钩子明确要求停止 |
在循环因为错误退出之前,系统会先尝试自我恢复。不同类型的问题,对应的处理方式也不一样:
提示太长:会先做一次「轻量清理」,删掉一些细节上下文,但保留整体结构。如果还是不够,就把整个上下文做一轮摘要压缩。再不行,才会报错退出。
输出 token 超限:如果响应太长导致中途被截断,会先提高输出上限再试一次。如果还不够,就从中断的地方继续生成,最多尝试 3 次。实在写不完,就返回当前已有的内容。
服务器过载(529):前台请求会用指数退避重试,尽量等服务恢复。但后台任务(比如摘要、分类、记忆)不会重试,避免在高负载时把压力放大。
模型回退:如果主模型一直返回 529,会切换到备用模型。切换时会清理当前状态,把未完成的内容标记掉,然后用新模型重新跑一轮。
高级特性:先思考后行动
前面讲的流程,其实是一个最简单的闭环:用户提问 → Claude 回答 → 调工具 → 返回结果。但真实任务往往没这么线性。比如你让 Claude Code 去「重构认证系统」,这通常意味着:涉及几十个文件,需要多轮分析和修改,还要保证过程不出错。
这时候,如果还是「想到什么就做什么」,很容易越改越乱。所以在真正动手之前,Agent 需要先做一件更重要的事:想清楚要怎么做,以及现在做到哪一步了。
Claude Code 为此提供了两个关键能力:
- 计划模式(Plan Mode):先拆解任务,明确步骤,再执行
- 任务(Tasks):在执行过程中持续跟踪进度,知道自己还差什么
Plan Mode:规划模式
Plan Mode 本质上只是权限系统里的一个「状态切换」。当 Claude 进入这个模式(可以是它自己决定,也可以是你触发),toolPermissionContext.mode 会被切到 'plan',同时把之前的模式存在 prePlanMode 里,方便后面恢复。
但真正的变化,其实不在权限,而在行为引导。
从技术上讲,什么都没被关掉:Claude 依然可以用所有工具,甚至还能改文件。
但系统会在上下文里加一段很明确的提示,大概意思就是:
在计划模式下,你应该按照以下步骤操作:
1. 仔细浏览代码库,了解已有的模式和结构
2. 找出类似功能或架构方案
3. 思考多种实现方式及其利弊
4. 如有需要,使用 AskUserQuestion 澄清方法
5. 制定具体的实施策略
6. 准备好后,用 ExitPlanMode 提交你的计划以供批准
注意:在这个阶段不要编写或修改任何文件,这是一个纯粹的只读探索和规划阶段。这里有个很关键的点:它不是靠「限制工具」,而是靠提示词去引导行为。
Claude 在计划模式下,其实仍然有写权限,但系统给出的指令非常明确:现在先探索,不要修改。实际效果也挺符合预期——它会去读文件、跑 grep、梳理代码结构,然后慢慢把一套可行的方案拼出来,而不是一上来就动手改代码。
计划生成之后,也不是直接执行。Claude 会把计划保存成一个文件,并在调用 ExitPlanMode 时,把这份计划展示给你确认。只有在你明确同意之后,系统才会恢复到进入计划模式之前的权限状态,同时把这份「已批准的计划」重新塞回上下文:
用户已批准你的计划,你现在可以开始编码。
在开始之前,如果需要,请先更新你的待办列表。
## 已批准的计划
1. 将认证逻辑从 `middleware.ts` 提取到 `auth/service.ts`
2. 更新登录处理程序以使用新的认证服务
3. 为认证服务编写单元测试
4. 更新相关的集成测试
5. 删除已弃用的认证助手现在 Claude 的状态就很清晰了:既有写权限,也有一份明确要执行的计划。接下来基本就是按步骤推进,而不是边想边改。
还有一个挺细节但很重要的设计:计划模式的提示是「有节制地出现」的。
它不会在每一轮都把完整的计划提醒重新塞一遍,而是做了几层控制:
- 有时候给完整提醒
- 有时候只给简化版本
- 如果最近刚提醒过,这一轮就直接跳过
这样做的目的很简单:避免这些规划提示反复出现,把上下文撑爆。
Tasks:任务系统
如果说 Plan Mode 解决的是「先想清楚再动手」,那 Tasks 解决的就是另一件事:做着做着,别把自己做丢了。
任务系统本质上很简单,就是一组围绕「任务状态」的工具:
TaskCreateTool:创建任务TaskGetTool:查看任务TaskUpdateTool:更新进度TaskListTool:列出所有任务
所有任务都会被存成一个 JSON 文件,落在磁盘上,算是一种很轻量的「外部记忆」。
{
id: string,
subject: string,
description: string,
status: 'pending' | 'in_progress' | 'completed',
blocks: string[], // 此任务阻止的任务 ID
blockedBy: string[], // 阻止此任务的任务 ID
owner: string, // 哪个 agent 拥有此任务
}任务之间其实是可以建立「依赖关系」的。通过 blocks 和 blockedBy 这两个字段,任务会形成一个简单的依赖图。比如任务 #3 被任务 #1 阻塞,那 Agent 就知道:#1 没做完之前,#3 不该动。这样就避免了「顺序错乱」或者提前动手导致返工。
但光有结构还不够,还得持续提醒。系统会定期检查:getTaskReminderAttachments() 检查 Agent 已经多久没碰任务系统了。如果时间有点久,就会往上下文里塞一个提醒,比如:你现在有 3 个待处理任务,1 个进行中。
这个提醒的作用很直接——把 Agent 拉回正轨,让它:更新进度、标记完成或者切换到下一个任务。更有意思的是,任务系统不只是单人用的,它是支持多 Agent 协作的。
当多个 Agent 一起工作时:
- 它们共享同一份任务列表(按团队,而不是按会话)
- 谁接手了任务,就会被标记为 owner
- 如果任务被重新分配,新的负责人会收到一条内部通知
也就是说,这套机制不仅在解决「我做到哪了」,还在解决:我们团队现在各自在做什么。
这些如何融入循环
Plan Mode 和 Tasks,其实并没有改变整个 Agent 循环的结构。循环还是那个循环:收集上下文 → 调模型 → 调工具 → 写回结果 → 进入下一轮。它们只是在循环内部工作。
从实现上看,一切都还是工具调用:
EnterPlanMode是一次工具调用TaskCreate是一次工具调用- 任务更新、退出计划模式,也全都是工具调用
而在每一轮开始时(步骤 1),上下文组装阶段会把这些状态一起带上:
- 当前是不是在 Plan Mode
- 当前有哪些任务、进度如何
和普通的工具结果一样,被模型「看到」。
可以把这个模式总结成一句话:Agent 用自己的工具,来管理自己的工作。它不是在一个外部系统里被调度,而是在对话里,一边思考、一边行动、一边更新自己的状态。
子智能体:不可避免的递归
在步骤 5 中,有时工具调用会是 AgentTool。当这种情况发生时,它会启动一个新的循环——递归地执行。
AgentTool 接收提示词、可选的 agent 类型和隔离设置:
const baseInputSchema = z.object({
description: z.string().describe('A short (3-5 word) description'),
prompt: z.string().describe('The task for the agent to perform'),
subagent_type: z.string().optional(),
model: z.enum(['sonnet', 'opus', 'haiku']).optional(),
run_in_background: z.boolean().optional(),
})在底层,调用 AgentTool 会启动一个全新的循环:
- 子智能体有自己独立的
query()循环 - 它有自己的消息历史,不会直接干扰主智能体
- 它有自己的工具上下文,并且只允许访问一部分工具
子智能体不能无限制地产生更多子智能体,也不能调用某些敏感或受限的工具。
三种隔离模式
隔离模式决定了子智能体和父智能体之间如何共享或隔离工作区:
- 同 CWD:子智能体和父智能体使用相同的工作目录。适合需要访问父级文件的研究或分析任务。
- Worktree:子智能体在仓库中有自己的
git worktree副本。它可以自由修改而不影响父智能体的工作。如果更改有用,可以合并到主分支;如果不需要,worktree 会自动清理。 - 后台:子智能体在后台异步运行。父智能体继续自己的任务,并在子智能体完成时收到通知。这样 Claude Code 可以一边做研究,一边帮你处理其他事情。
递归设计的复杂度边界
子智能体在代码库中并不是特别「神秘」。它就是一个缩小版的 query() 循环——使用相同的工具系统、权限模型和上下文压缩逻辑,只是范围更小、工具更受限。
当子智能体完成任务时,它的输出就像普通工具结果一样流回父循环。父智能体无需区分它和普通工具调用。
这种设计保证了复杂度是可控的:
- 没有单独的「Agent 运行器」或「任务执行器」需要管理。
- 顶层循环的压缩和错误恢复策略,同样适用于子智能体。
- 每个子智能体都是父循环的一部分,不会引入不可控的复杂性。
简单来说,递归的边界很清楚:子智能体的行为完全在父循环管理之下。
结语:Harness
从用户发送一条消息到整个 Agent 循环完成,我们看到 Claude Code 是如何运作的:
- 上下文组装:系统提示词、各目录下的
CLAUDE.md、持久记忆和技能一起组成完整上下文 - 异步循环:响应是流式返回的,工具调用和状态更新在后台并行进行
- 工具体系:内置工具加上 MCP 工具统一走同一套权限机制
- 权限控制:读操作默认放行,写操作需要确认或额外判断
- 执行策略:读操作可以并发,写操作串行执行,避免冲突
- 反馈循环:工具结果会回到上下文里,影响后续决策
- 长会话处理:通过多种压缩策略控制上下文长度
- 错误恢复:针对不同类型的问题都有兜底机制
- 递归子智能体:支持递归调用,但范围和权限都是受控的
整体来看,Claude Code 更像一个完整的 Agent 执行框架,而不是简单的对话工具。它把规划、执行、反馈这些环节串成一个闭环,让复杂任务可以自动推进,同时又不至于失控。
如果你也在做 AI Agent,很多精力其实都会花在这套运行机制(Harness)上,这部分往往才是最有价值的地方。
Post Link: 深入理解 Claude Code 源码中的 Agent Harness 构建之道